I have worked with Cetis in one way or another for about 15 years, but am very happy to announce that at the end of last week I became a partner of Cetis LLP. Continue reading
Category Archives: cetis
Translating course descriptions from XCRI-CAP to schema.org
XCRI-CAP (eXchanging Course Related Information, Course Advertising Profile) is the UK standard for course marketing information in Higher Education. It is compatible with the European Standard Metadata for Learning Opportunities. The W3C schema course extension community group has developed terms for describing educational courses that are now part of schema.org. Here I look at translating the data from an XCRI-CAP xml feed to schema.org json-ld. Continue reading
Schema course extension progress update
I am chair of the Schema Course Extension W3C Community Group, which aims to develop an extension for schema.org concerning the discovery of any type of educational course. This progress update is cross-posted from there.
If the forming-storming-norming-performing model of group development still has any currency, then I am pretty sure that February was the “storming” phase. There was a lot of discussion, much of it around the modelling of the basic entities for describing courses and how they relate to core types in schema (the Modelling Course and CourseOffering & Course, a new dawn? threads). Pleased to say that the discussion did its job, and we achieved some sort of consensus (norming) around modelling courses in two parts
Course, a subtype of CreativeWork: A description of an educational course which may be offered as distinct instances at different times and places, or through different media or modes of study. An educational course is a sequence of one or more educational events and/or creative works which aims to build knowledge, competence or ability of learners.
CourseInstance, a subtype of Event: An instance of a Course offered at a specific time and place or through specific media or mode of study or to a specific section of students.
hasCourseInstance, a property of Course with expected range CourseInstance: An offering of the course at a specific time and place or through specific media or mode of study or to a specific section of students.
(see Modelling Course and CourseInstance on the group wiki)
This modelling, especially the subtyping from existing schema.org types allows us to meet many of the requirements arising from the use cases quite simply. For example, the cost of a course instance can be provided using the offers property of schema.org/Event.
The wiki is working to a reasonable extent as a place to record the outcomes of the discussion. Working from the outline use cases page you can see which requirements have pages, and those pages that exist point to the relevant discussion threads in the mail list and, where we have got this far, describe the current solution. The wiki is also the place to find examples for testing whether the proposed solution can be used to mark up real course information.
As well as the wiki, we have the proposal on github, which can be used to build working test instances on appspot showing the proposed changes to the schema.org site.
The next phase of the work should see us performing, working through the requirements from the use cases and showing how they can be me. I think we should focus first on those that look easy to do with existing properties of schema.org/Event and schema.org/CreativeWork.
HECoS, a new subject coding system for Higher Education
You may have missed that just before Christmas HECoS (the Higher Education Classification of Subjects) was announced. I worked a little on the project that lead up to this, along with colleagues in Cetis (who lead the project), Alan Paull Serices and Gill Ferrell, so I am especially pleased to see it come to fruition. I believe that as a flexible classification scheme built on semantic web / linked data principles it is a significant contribution to how we share data in HE.
HECoS was commissioned as part of the Higher Education Data & Information Improvement Programme (HEDIIP) in order to find a replacement to JACS, the subject coding scheme currently used in UK HE when information from different institutions needs to be classified by subject. When I was first approached by Gill Ferrell while she was working on a preliminary study of to determine if it needed changing, my initial response was that something which was much more in tune with semantic web principles would be very welcome (see the second part of this post that I wrote back in 2013). HECoS has been designed from the outset to be semantic web friendly. Also, one of the issues identified by the initial study was that aggregation of subjects was politically sensitive. For starters, the level of funding can depend on whether a subject is, for example, a STEM subject or not; but there are also factors of how universities as institutions are organised into departments/faculties/schools and how academics identify with disciplines. These lead to unnecessary difficulties in subject classification of courses: it is easy enough to decide whether a course is about ‘actuarial science’ but deciding whether ‘actuarial science’ should be grouped under ‘business studies’ or ‘mathematics’ is strongly context dependent. One of the decisions taken in designing HECoS was to separate the politics of how to aggregate subjects from the descriptions of those subjects and their more general relationships to each other. This is in marked contrast to JACS where the aggregation was baked into the very identifiers used. That is not to say that aggregation hierarchies aren’t important or won’t exist: they are, and they will, indeed there is already one for the purpose of displaying subjects for navigation, but they will be created through a governance process that can consider the politics involved separately from describing the subjects. This should make the subject classification terms more widely usable, allowing institutions and agencies who use it to build hierarchies for presentation and analysis that meet their own needs if these are different from those represented by the process responsible for the standard hierarchy. A more widely used classification scheme will have benefits for the information improvement envisaged by HEDIIP.
The next phase of HECoS will be about implementation and adoption, for example the creation of the governance processes detailed in the reports, moving HECoS up to proper 5-star linked data, help with migration from JACS to HECoS and so on. There’s a useful summary report on the HEDIIP site, and a spreadsheet of the coding system itself. There’s also still the development version Cetis used for consultation, which better represents its semantic webbiness but is non-definitive and temporary.
A library shaped black hole in the web?
A library shaped black hole in the web? was the name of an OCLC event that was getting its second(?) run in Edinburgh last week, looking at how libraries can contribute to the web, using new technologies (for example linked data) to “re-envision, expose and share library data as entities (work, people, places, etc.) and what this means.”
Aside: to suggest that libraries act as a black hole in the web is quite a strong statement, you see black holes suck in information and at the very least mangle it, if not destroy it completely. Perhaps only a former physicist would read the title that way 🙂
We were promised that we would:
learn how entity-based descriptions of library data – powered by linked data – will create new approaches to cataloguing, resource sharing and discovery. We will look at how referencing library data as entities, in Web friendly formats, enables data relationships to be rendered useful in many more contexts increasing the relevance of libraries within the wider information ecosystem.
which I wouldn’t quibble with. Here’s a summary of what I did take from the day.
Owen Stephens got us started with an introduction to the basic RDF model of triples building in to a graph, pointing out that the basic services required to start doing this are not already available to libraries. So if the statement you wish to make is about the authorship of a book, you need URIs to identify the book, the person and the “has creator” relationship: these first two of these are provided by, for example, the Library of Congress Authorities linked data service, the third by Dublin Core (among others). But Owen stressed that the linked data approach was more than another view of the same data because other people can make statements about your data. Owen drew on the distinction made in the Semantic Web community between “open world” and “closed world” approaches to illustrate how this can change your view of data. The library-catalogue-as-inventory is treated “closed world”, that is that all the relevant information could be assumed to be there, so if you don’t have information about a book in your inventory then you infer that you don’t have the book. In an open world, however, someone else might have information that would change that inference, so in an open world approach to using data you wouldn’t take lack of information about something to mean that the thing in question did not exist. The advantage of working in an open world is that further information is always being added by others from other fields, so the catalogue-as-information-source can be just one source of data for a web that goes beyond bibliographic data. Owen gave an example of this from Early English Books, where data extracted from the colophons about the booksellers who had commissioned the printing of each book had been linked to data from historical research on these book sellers (their locations and dates of operation) which greatly enhances the value of the library catalogue data for researchers into the history of publishing. We’ll come back to this theme of enhancing the value of the library catalogue for others.
Owen has a more complete summary of his presentation available.
Neil Jefferies of the Bodleian library built on what Owen had been discussing. He identified the core interest of the library as the intellectual content of the books, letting archives and museums deal with the book as an object, and he mentioned the hierarchical nature of intellectual content: data -> facts -> information -> knowledge. He also added that the libraries key strengths of the library are expertise in retention and search, and access to the physical originals. technology thought has shifted what the library may achieve, so that it should be about creating knowledge not just holding data or sharing information. He went on to give more examples of projects showing libraries using linked data to facilitate knowledge creation than I could manage to take notes on, but a among the highlights was: LD4L, Linked data for libraries, a $999k Mellon funded project involving Cornell, Harvard and Standford, which aims to create a “Scholarly Resource Semantic Information Store” which works both within individual institutions and links to other domains. the aim is to build this with OSS, and Neil mentioned the VIVO platform and community as an example of this. Neil also spoke about the richness required in order to model all the information relevant to knowledge in the library. CAMELOT is the data model used for knowledge held at the Bodleian, it includes a lot of provenance and contextual modelling: linked data is about assertions and you need context and provenance to be able to judge the truth of these (here’s a consequence of the open world nature of linked data, do you know where your data came from? do you know the assumptions made when creating it?). BIBFRAME, or MARC in RDF is not enough, it holds on to the idea of central authority of the catalogue(-as-inventory), and in linked data authority is more diffuse. The data model for LD4L will likely include BIBFRAME, FaBIO, VIVO-ISF, OpenAnnotation, PAV, OAI-ORE, SKOS, VIAF, ORCHID, ISNI, OCLC Works, circulation, citation and usage data, and will likely need a deal of entity reconciliation to deal with many people talking about the same thing.
So much for the idea and the promise of linked data for libraries. I would next like to describe a trio of talks that dealt with the question “what is to be done?”
Cathy Dolbear from Oxford University Press spoke about providing semantic and bibliographic data for libraries. The OUP provide metadata in a lot of different ways, varying from the venerable OAI-PMH (which seems to have little uptake) to RDFa embedded in product web pages (which may soon become JSON-LD). And yet most people find OUP content via direct links and search engines, a spot sample of one day’s referrers showed library discovery services accounted for ~1% of the hits. Cathy stressed that there were patches where library discovery services were more significant, but on the whole it was hard to see library use. Internally OUP have their own schema, OxMetaML, and are moving to a more graph-based approach; the transform this to the standard used by discovery services, e.g. HighWire, PRISM, JATS, PubMED etc. Cathy seemed to want to find ways that OUP metadata could be used to support the endeavours of libraries to use linked data as described above, but wanted to know that if she published Linked Data how would it be used–OUP can only spend money on doing things they know people are going to use, but it is hard to see who is using linked data. I got the strong impression that Cathy knew the ideas, and was aware of the project work being done with linked data, but her key point was that OUP need more info from libraries about what data is needed for real-world service delivery before they can be sure whether it’s worth creating & delivering metadata.
Ken Chad spoke about Linked data why care and what do we do describing the current status of linked data in terms of chasms in the technology adoption lifecycle and troughs of disillusionment in the hype cycle, both of which echo Cathy’s question about how do we get beyond interesting projects and to real world service delivery. In my own mind this is key. The initial draft of RDF is about 18 years old. The “linked data” reboot is about 9 years old. When do we stop talking about early adopters and decide we’ve got all the adopters we’re going to get? Or at least if we want more adopters we need a radically different approach. Ken spoke about approaching the problem in terms of the Jobs to be Done–the link to Ken’s presentation above describes that approach–which I have no problem with, and I certainly would agree with Ken’s suggestion that the job to be done is to “design a library website that helps students focus less on finding and more on studying”. However, I do think there is an extra layer to this problem in that it requires other people to provide things you can link to. Buying a phone won’t help get a job done if you’re the only person with a phone.
Gill Hamilton of the National Library of Scotland to the theme of how to be ready for linked data even if you’re not convinced. This appealed to me. She gave three top tips: (1) following google, think of things not strings and record URIs not names; (2) you probably need a rich and detailed schema for your own specialised uses of the data, don’t dumb this down to a generic ontology but publish it and map to the generic; (3) concentrate on what you have that’s unique and let other people handle the generic. To these Gill added three lesser tips: license your metadata as CC0, demand better systems and use open vocabularies.
Richard Wallis gave the final presentation ” the web of data is our oyster” which he stated by describing a view of the development of the web from a web of documents to a web of dynamic documents, to a web of information discovery to a web of data to a web of knowledge (with knowledge graphs and data mining). He suggested that libraries were engaged at the start, but became disengage, maybe even hostile, at the point of the the web of discovery. One change that libraries had missed through this was the move from records (by definition, relating to the past) to living descriptions in terms of entities and relationships. This he suggested had meant that many library projects on sharing data had lead to “linked data silos” which search engines cannot get into. The current approach to giving search engines access to entity and relationship data is schema.org, and Richard described his own work on extending schema for bibliographic data. Echoing Gill’s second tip he stressed that this was not intended to be an appropriate way to meet the libraries metadata needs, or even the way that libraries should use the web to share data between themselves, but it is a way that libraries can share their data with the web (of discovery, of data, of knowledge) as whole.
All in all, a good day. Nothing spectacularly new, but useful to see it all lined up and presented so coherently. Many thanks to Owen, Neil, Cathy, Ken, Gill and Richard, and to OCLC for arranging the event.
Presentation: LRMI – using schema.org to facilitate educational resource discovery on the web and beyond
Today I am in London for the ISKO Knowledge Organisation in Learning and Teaching meeting, where I am presenting on LRMI and schema.org to facilitate educational resource discovery on the web and beyond. My slides are here, mostly they cover similar ground to presentations I’ve given before which have been captured on video or which I have written up in more detail. So here I’ll just point to my slides for today (& below) and summarise the new stuff.
LRMI uptake
People always want to know how much LRMI exists in the wild, and now schema.org reports this infomation. Go to the schema.org page for any class or property and at the top it says in how many domains they find markup for it. Obviously this misses that not all domains are equal in extent or importance: finding LRMI on pjjk,net should not count as equal to finding it on bbc.co.uk, but as a broad indicator it’s OK: finding a property on 10 domains or 10,000 domains is a valid comarison. LRMI properties are mostly reported as found on 100-1000 domains (e.g. learning resource type) or 10-100 domains (e.g. educational alignment). A couple of LRMI properties have greater usage, e.g. typical age range and is based on URL (10-50,00 and 1-10,000 domains respectively), but I guess that reflects their generic usefulness beyond learning resources. We know that in some cases LRMI is used for internal systems but not exposed on web pages, but still the level of usage is not as high as we would like.
I also often get asked about support for creating LRMI metadata, this time I’m including a mention of how it is possible to write WordPress plugins and themes with schema / LRMI support, and the drupal schema.org plugin. I’m also aware of “tagging tools” associated with various repositories, e.g. the learning registry and the Illinois Shared Learning Environment. I think it’s always going to be difficult to answer this one as the best support will always come from customising whatever CMS an organisation uses to manage their content or metadata and will be tailored to their workflow and the types of resources and educational contexts they work in.
As far implementation for search I still cover google custom search, as in the previous presentations.
Current LRMI activities
The DCMI LRMI task group is active, one of our priorities is to improve the support for people who want to use LRMI. Two activities are nearing fruitition: firstly, we are hoping to provide examples for relevant properties and type on the schema.org web site. Secondly, we want to provide better support for the vocabularies used for properties such as alignment type (in the Alignment Object), learning resource type etc, by way of clear definitions and machine readable vocabulary encodings (using SKOS). We are asking for public review and comment on LRMI vocabularies, so please take a look and get in touch.
Other work in progress is around schema for courses and extending some of the vocabularies mentioned above. We have monthly calls, if you would like to lend a hand please do get in touch.
LRMI examples for schema.org
It’s been over two years since the LRMI properties were added to schema.org. One thing that we should have done much sooner is to create simple examples of how they can be used for the schema.org website (see, for example, the bottom of the Creative Work page). We’re nearly there.
We have two examples in the final stages of preparation, so close to ready that you can see previews of what we propose to add (at the bottom of that page).
The first example is very simple, just a few lines describing a lesson plan for US second grade teachers (NB, the lesson plan itself is not included in the example):
<div> <h1>Designing a treasure map</h1> <p>Resource type: lesson plan, learning activity</p> <p>Target audience: teachers</p> <p>Educational level: US Grade 2</p> <p>Location: <a href="http://example.org/lessonplan">http://example.org/lessonplan</a></p> </div>
With added microdata that becomes
<div itemscope itemtype="http://schema.org/CreativeWork">
<h1 itemprop="name">Designing a treasure map</h1>
<p>Resource type:
<span itemprop="learningResourceType">lesson plan</span>,
<span itemprop="learningResourceType">learning activity</span>
</p>
<p>Target audience:
<span itemprop="audience" itemscope itemtype="http://schema.org/EducationalAudience">
<span itemprop="educationalRole">teacher</span></span>s.
</p>
<p itemprop="educationalAlignment" itemscope itemtype="http://schema.org/AlignmentObject">
<span itemprop="alignmentType">Educational level</span>:
<span itemprop="educationalFramework">US Grade Levels</span>
<span itemprop="targetName">2</span>
<link itemprop="targetUrl" href="http://purl.org/ASN/scheme/ASNEducationLevel/2" />
</p>
<p>Location: <a itemprop="url" href="http://example.org/lessonplan">http://example.org/lessonplan</a></p>
</div>
(Other flavours of schema.org markup are at the bottom of the AlignmentObject preview.)
This is illustrates a few points:
- free text learning resource types, which can be repeated
- the audience for the resource (teachers) is different from the grade level of the end users (pupils)
- educationalRole is a property of EducationalAudience, not the CreativeWork being described
- how the AlignmentObject should be used to specify the grade level appropriateness of the resource
- human readable grade level information is supplemented with a machine readable URI as the targetUrl
The second example is more substantial. It is based on a resource from BBC bitesize (though we have hacked the HTML around a bit). Here’s the HTML
<div>
<h1>The Declaration of Arbroath</h1>
<p>A lesson plan for teachers with associated video.
Typical length of lesson, 1 hour.
Recommended for children aged 10-12 years old.
</p>
<p>Subject: Wars of Scottish independence</p>
<p>Alignment to curriculum:</p>
<ul>
<li>England
National Curriculum: KS 3 History: The middle ages (12th to 15th century)
</li>
<li>Scotland
SCQF: Level 2
Curriculum for Excellence: Social studies: people past events and societies: The Wars of Independence
</li>
</ul>
<p>Location: <a href="http://example.org/lessonplan">http://example.org/lessonplan</a></p>
<video>
<source src="http://example.org/movie.mp4" type="video/mp4" />
Duration 03:12
</video>
</div>
and here’s the JSON-LD:
<script type="application/ld+json">
{
"@context": "http://schema.org/",
"@type": "WebPage",
"name": "The Declaration of Arbroath",
"about": "Wars of Scottish independence",
"learningResourceType": "lesson plan",
"timeRequired": "1 hour",
"typicalAgeRange": "10-12",
"audience": {
"@type": "EducationalAudience",
"educationalRole": "teacher"
},
"educationalAlignment": [
{
"@type": "AlignmentObject",
"alignmentType": "educationalSubject",
"educationalFramework": " Curriculum for Excellence: ",
"targetName": "Social studies: people past events and societies",
"targetUrl": "http://example.org/CFE/subjects/3362"
},
{
"@type": "AlignmentObject",
"alignmentType": "educationalLevel",
"educationalFramework": "SCQF",
"targetName": "Level 2",
"targetUrl": "http://example.org/SCQF/levels/2"
},
{
"@type": "AlignmentObject",
"alignmentType": "educationalLevel",
"educationalFramework": "National Curriculum",
"targetName": "KS 3",
"targetUrl": "http://example.org/ENC/levels/KS3"
},
{
"@type": "AlignmentObject",
"alignmentType": "educationalSubject",
"educationalFramework": "National Curriculum",
"targetName": "History: The middle ages (12th to 15th century)",
"targetUrl" : "http://example.org/ENC/subjects/3102"
}
],
"url" : "http://example.org/lessonplan",
"video": {
"@type": "VideoObject",
"description": "Video description",
"duration": "03:12",
"name": "Video Title",
"thumbnailUrl": "http://example.org/thubnail.mp4",
"uploadDate": "2000-01-01",
"url" : "http://example.org/movie.mp4"
}
}
</script>
(Again other flavours of schema.org markup are at the bottom of the AlignmentObject preview.)
The additional points to note here are that
- we chose to mark up the lesson plan as the learning resource rather than the video. Nothing wrong with marking up the video as a learning resource, but things like educational alignment will be more explicit for lesson plans. (Again, neither the lesson plan nor the video are in the example)
- the typical learning time of the lesson plan is not the same as the duration of the video
- this example treat the English and Scottish curricula as providing subjects for study at given educational levels. It would be possible to go deeper and align to specific competence statements (e.g. say that the alignment is that the resource “teaches” Curriculum for Excellence outcome SOC 2-01a “I can use primary and secondary sources selectively to research events in the past.”
- the educational subject (i.e. the educational context of the resource in terms of those subjects studied at school) is different from the topic that the resource is about
- it’s a shame that there are no real URIs to use for the targets of these aligments
- while you can omit the url property for the described resource, we thought it safer to include it; the default value is the URI of the webpage in which the markup is included, which may be what you need, but in the case of stand-alone JSON-LD you’re lost without an explicit value for “url”
As ever, comments would be welcome.
A short project on linking course data
Alasdair Gray and I have had Anna Grant working with us for the last 12 weeks on an Equate Scotland Technology Placement project looking at how we can represent course information as linked data. As I wrote at the beginning of the project, for me this was of interest in relation to work on the use of schema.org to describe courses; for the department as a whole it relates to how we can access course-related information internally to view information such as the articulation of related learning outcomes from courses at different stages of a programme, and how data could be published and linked to datasets from other organisations such as accrediting bodies or funders. We avoided any student-related data such as enrolments and grades. The objectives for Anna’s work were ambitious: survey existing HE open data and ontologies in use; design an ontology that we can use; develop an interface we can use to create and publish our course data. Anna made great progress on all three fronts. Most of what follows is lifted from her report.
(Aside: at HW we run 4-year programmes in computer science which are composed of courses; I know many other institution run 3/4-year courses which are comprised of modules. Talking more generally, course is usefully ambiguous to cover both levels of granularity; programme and module seem unambiguous.)
A few Universities have already embarked on a similar projects, notably the Open University, Oxford University and Southampton University in the UK, and Muenster and the American University of Beirut elsewhere. Southampton was one of the first Universities to take the open linked data approached and as such they developed their own bespoke ontology. Oxford has predominantly used the XCRI ontology (see below for information on the standard education ontologies mentioned here) to represent data, additionally they have used MLO, dcterms, skos and a few resource types that they have defined in their own ontology. The Open University has the richest data available, the approach they took was to use many ontologies. Muenster developed the TEACH ontology, and the American University of Beirut used the CourseWare and AIISO ontologies.
The ontologies reviewed were: AIISO, Teach, CourseWare, XCRI, MLO, ECIM and CEDS. A live working draft of the summary / review for these is available for comment as a Google Doc.
Aiiso (Academic Institution Internal Structure Ontology) is an excellent ontology for what it is designed for but as it says, it aims to describe the structure of an institution and doesn’t offer a huge amount in the way of particular properties of a course. Teach is a better fit in terms of having the kind of properties that we wished to use to describe a course, however doesn’t give any kind of representation of the provider of the course. CourseWare is a simple ontology with only four classes and many properties with with Course as the domain, the trouble with this ontology is that it is closely related to the Aktors ontology which is no longer defined anywhere online.
XCRI and MLO are designed for the advertising of courses and as such they miss out some of the features of a course that would be represented in internal course descriptions such as assessment method and learning outcomes. Neither of these ontologies show the difference between a programme and a module. ECIM is an extension of MLO which provides a common format for representing credits awarded for completion of a learning opportunity.
CEDS (Common Education Data Standards) is an American ontology which provides a shared vocabulary for educational data from preschool right up to adult education. The benefits of which are, that data can be compared and exchanged in a consistent way. It has data domains for assessment, learning standards, learning resources, authentication and authorisation. Additionally it provides domains for different stages of education e.g. post-secondary education. CEDS is ambitious in that it represents all levels of education and as such is a very complex and detailed ontology.
XCRI, MLO (+ ECIM) and CEDS can be grouped together in that they differentiate between a course specification and a course instance, offering or section. The specification being the parts of a course that remain consistent from one presentation to the next, whereas the instance defines those aspects of a course that vary between presentations for example location or start date. The advantage of this is that there will be a smaller amount of data that will require updating between years/offerings.
An initial draft of a Heriot Watt schema applying all the ontologies available was made. It was a mess, however it became apparent the MLO was the predominant ontology. So we chose to use MLO where possible and then use other ontologies where required. This iteration resulted in a course instance becoming both an MLO learning opportunity instance and a TEACH course in order to be able to use all the properties required. Even using this mix of ontologies we still needed to mint our own terms. This approach was a bit complex and TEACH does not seem to be widely used, we therefore decided to use MLO alone and extend it to fit our data in a similar way that already started by ECIM.
The final draft is shown below. Key: Green= MLO, Purple=MLO extension, Blue=ECIM / previous alteration to MLO Yellow= generic ontologies such as Dublin core and SKOS. In brief, we used subtypes of MLO Learning Opportunities to describe both programmes and modules. The distinction between information that is at the course specification level and that which is at the course instance level was made on the basis of whether changing the information required committee approval. So things that can be changed year on year without approval such as location, course leader and other teaching staff are associated with course instance; things that are more stable and require approval such as syllabus, learning outcomes, assessment methods are at course specification level.
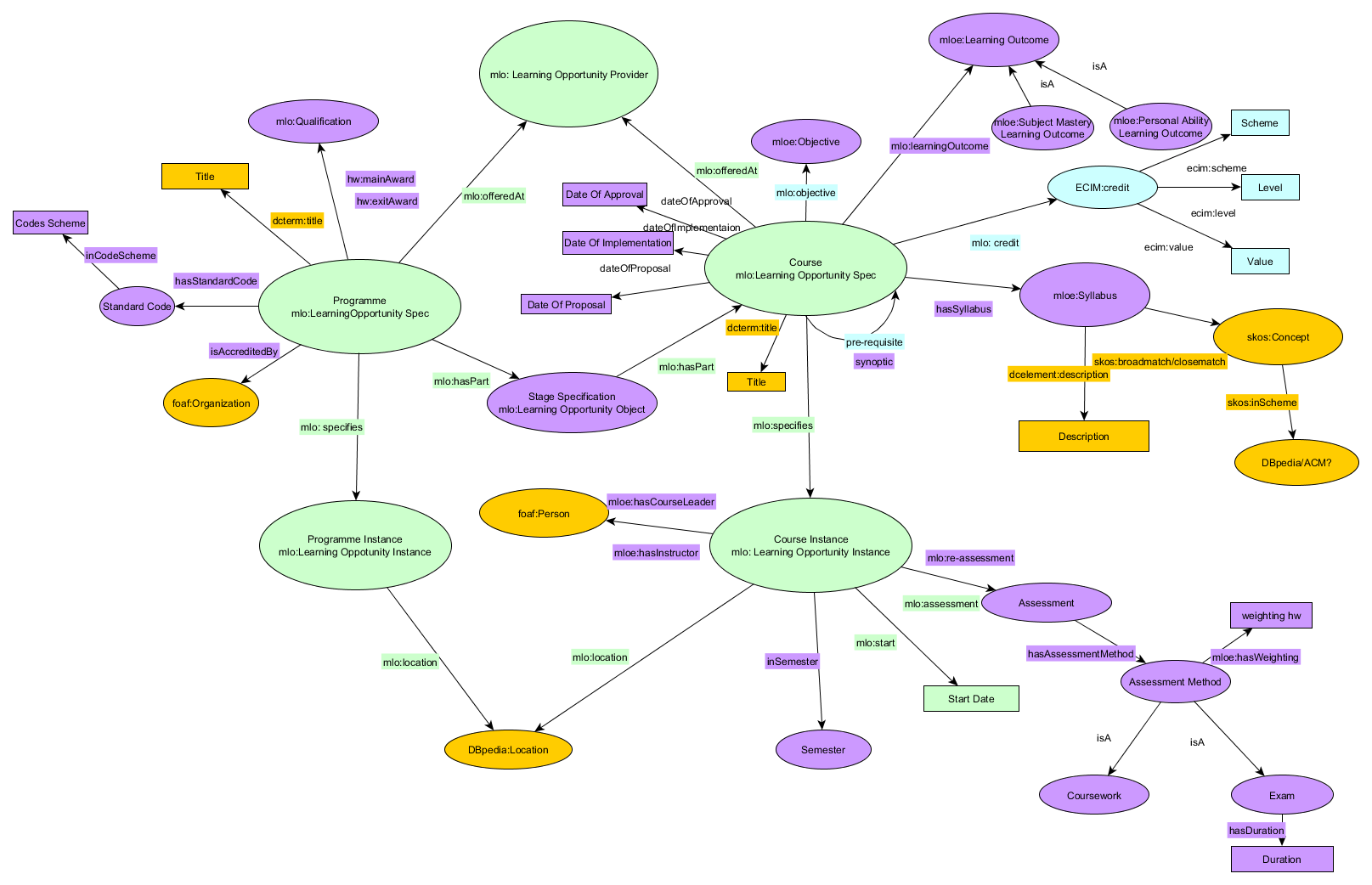
We also created some instance data for Computer Science courses at Heriot-Watt. For this we use Semantic MediaWiki (with the Semantic bundle). Semantic forms were used for inputting course information, the input from the forms is then shown as a wiki page. Categories in mediawiki are akin to classes, properties are used to link one page to another and also to relate the subject of the page to its associated literals. An input form has the properties inbuilt such that each field in the form has a property related to it. Essentially the item described by the form will become the object in the stored triple, the property associated with a field within the form will form the predicate of the stored triple and the input to the field will form the subject of a triple. A field can be set such that multiple values can be entered if separated by commas, and in this case a triple will be formed for each value. I think there is a useful piece of work that could be done comparing various tools for creating linked data (e.g. Semantic MediaWiki, Calimachus, Marmotta) and evaluating whether other approaches (e.g. WordPress extensions) may improve on them. If you know of anything along such lines please let me know.
We have little more work to do in representing the ontology in Protege and creating more instance data, watch this space for updates and a more detailed description than the image above. We would also like to evaluate the ontology more fully against potential use cases and against other institutions data.
Anna has finished her work here now and returns to Edinburgh Napier University to finish her Master’s project. Alasdair and I think she has done a really impressive job, not least considering she had no previous experience with RDF and semantic technologies. We’ve also found her a pleasure to work with and would like to thank her for her efforts on this project.
WordPress as a semantic web platform?
For the work we’ve been doing on semantic description of courses we needed a platform for creating and editing instance data flexibly and easily. We looked at callimachus and Semantic MediaWiki; in the end we went with the latter because of JAVA version incompatibility problems with the other, but it has been a bit of a struggle. I’ve used WordPress for publishing information about resources on a couple of projects, for Cetis publications and for learning resources, and have been very happy with it. WordPress handles the general task of publishing stuff on the web really well, it is easily extensible through plugins and themes, I have nearly always found plugins that allow me to do what I want and themes that with a little customization allow me to present the information how I want. As a piece of open source software it is used on a massive scale (about a quarter of all web domains use it) and has the development effort and user support to match. For the previous projects my approach was to have a post for each resource I wanted to describe and to set the title, publication date and author to be those for the resource, I used the main body of the post for a description and used tags and categories for classification, e.g. by topic or resource type; other metadata could be added using WordPress’s Custom Fields, more or less as free text name-value pairs. While I had modified themes so that the semantics of some of this information was marked up with microdata or RDFa embedded in the HTML, I was aware that WordPress allowed for more than I was doing.
The possibility of using WordPress for creating and publishing semantic data hinges on two capabilities that I hadn’t used before: firstly the ability to create custom post types so that for each resource type there can be a corresponding post type; secondly the ability to create custom metadata fields that go beyond free text. I used these in conjunction with a theme which is a child theme of the current default, TwentyFifteen, which sets up the required custom types and displays them. Because I am familiar with it and it is quite general purpose, I chose the schema.org ontology to implement, but I think the ideas in this post would be applicable to any RDF vocabulary. When creating examples I had in mind a dataset describing the books that I own and the authors I am interested in.
I started by using a plugin, Custom Post Type UI, to create the post types I wanted but eventually was doing enough in php as a theme extensions (see below) that it made sense just to add a function to create the the post types. This drops the dependency on the plugin (though it’s a good one) and means the theme works from the outset without requiring custom types to be set up manually.
add_action( 'init', 'create_creativework_type' );
function create_creativework_type() {
register_post_type( 'creativework',
array(
'labels' => array(
'name' => __( 'Creative Works' ),
'singular_name' => __( 'Creative Work' )
),
'public' => true,
'has_archive' => true,
'rewrite' => array('slug' => 'creativework'),
'supports' => array('title', 'thumbnail', 'revisions' )
)
);
}
The key call here is to the WP function register_post_type() which is used to create a post type with the same name as the schema.org resource type / class; so I have one of these for each of the schema.org types I use (so far Thing, CreativeWork, Book and Person). This is hooked into the WordPress init process so it is done by the time you need those post types.
I do use a plugin to help create the custom metadata fields for every property except the name property (for which I use the title of the post). Meta Box extends the WordPress API with some functions that make creating metadata fields in php much easier. These metadata fields can be tailored for particular data types, e.g. text, dates, numbers, urls and, crucially, links to other posts. That last one gives you what you need for to create relationships between the resources you describe in WordPress, which can expressed as triples. Several of these custom fields can be grouped together into a “meta box” and attached as a group to specific post types so that they are displayed when editing posts of those types. Here’s what declaring a custom metadata field for the author relationship between a CreativeWork and a Person looks like with MetaBox (for simplicity I’ve omitted the code I have for declaring the other properties of a Creative Work and some of the optional parameters). I’m using the author property as an example because a repeatable link to another resource is about as complicated a property as you get.
function semwp_register_creativework_meta_boxes( $meta_boxes )
{
$prefix = 'semwp_creativework_';
// 1st meta box
$meta_boxes[] = array(
'id' => 'main_creativework_info',
'title' => __( 'Main properties of a schema.org Creative Work', 'semwp_creativework_' ),
// attach this box to the following post types
'post_types' => array('creativework', 'book' ),
// List of meta fields
'fields' => array(
// Author
// Link to posts of type Person.
array(
'name' => __( 'Author (person)', 'semwp_creativework_' ),
'id' => "{$prefix}authors",
'type' => 'post',
'post_type' => 'person',
'placeholder' => __( 'Select an Item', 'semwp_creativework_' ),
// set clone to true for repeatable fields
'clone' => true
),
),
);
return $meta_boxes;
}
What this gives when editing a post of type book is this:

WordPress uses a series of nested templates to display content, which are defined in the theme and can either be specific to a post type or generic, the generic ones being used as a fall back if a more specific one does not exist. As I mentioned I use a child theme of TwentyFifteen which means that I only have to include those files that I change from the parent. To display the main content of posts of type book I need a file called content-book.php (the rest of the page is common to all types of post), which looks like this
<article resource="?<?php the_ID() ; ?>#id" id="?<?php the_ID(); ?>" <?php post_class(); ?> vocab="http://schema.org/" typeof="Book">
<header class="entry-header">
<?php
if ( is_single() ) :
the_title( '<h1 class="entry-title" property="name">', '</h1>' );
else :
the_title( sprintf( '<h2 class="entry-title"><;a href="%s" rel="bookmark">', esc_url( get_permalink() ) ), '</a></h2>;' );
endif;
?>
</header>
<div class="entry-content">
<?php semwp_print_creativework_author(); ?>
<?php semwp_print_book_bookEdition(); ?>
<?php semwp_print_book_numberOfPages(); ?>
<?php semwp_print_book_isbn(); ?>
<?php semwp_print_book_illustrator(); ?>
<?php semwp_print_creativework_datePublished(); ?>
<?php semwp_print_book_bookFormat(); ?>
<?php semwp_print_creativework_sameAs(); ?></div>
<footer class="entry-footer">
<?php twentyfifteen_entry_meta(); ?>
<?php edit_post_link( __( 'Edit', 'twentyfifteen' ), '<span class="edit-link">', '</span>' ); ?>
<?php semwp_print_extract_rdf_links(); ?>
</footer>
</article>
Note the RDFa in some of the html tags, for example the <article> tag includes
resource= [url]#id vocab="http://schema.org/" typeof="Book"
and the title is output in an <h1> tag with the
property="name"
attribute. Exposing semantic data as RDFa is one (good) thing, but what about other formats? A useful web service called RDF Translator helps here. It has an API which allowed me to put a link at the foot of each resource page to the semantic data from that page in formats such as RDF/XML, N3 and JSON-LD; it’s quite not what you would want for fully fledged semantic data publishing but it does show the different views of the data that can be extracted from what is published.
Also note that most of the content is printed through calls to php functions that I defined for each property, semwp_print_creativework_author() looks like this (again a repeatable link to another resource is about as complex as it gets:
function semwp_print_alink($id) {
if (get_the_title($id)) //it's a object with a title
{
echo sprintf('<a property="url" href="%s"><span property="name">%s</span></a>', esc_url(get_permalink($id)), get_the_title($id) );
}
else //treat it as a url
{
echo sprintf('<a href="%s">%s</a>', esc_url($id), $id );
}
}
function semwp_print_creativework_author()
{
if ( rwmb_meta( 'semwp_creativework_authors' ) )
{
echo '
By: ';
$authors = rwmb_meta( 'semwp_creativework_authors' );
foreach ( $authors as $author )
{
echo '<span property="author" typeof="Person">';
semwp_print_alink($author);
echo '</span>';
}
echo '
';
}
}
So in summary, for each resource type I have two files of php/html code: one which sets up a custom post type, custom metadata fields for the properties of that type (and any other types which inherit them) and includes some functions that facilitate the output of instance data as HTML with RDFa; and another file which is the WordPress template for presenting that data. Apart from a few generally useful functions related to output as HTML and modifications to other theme files (mostly to remove embedded data which I found distracting) that’s all that is required.
The result looks like this:

And here’s the N3 rendering of the data in that page as converted by RDF Translator:
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> . @prefix rdfa: <http://www.w3.org/ns/rdfa#> . @prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> . @prefix schema: <http://schema.org/> . @prefix xml: <http://www.w3.org/XML/1998/namespace> . @prefix xsd: <http://www.w3.org/2001/XMLSchema#> . <http://www.pjjk.net/semanticwp/book/the-day-of-the-triffids> rdfa:usesVocabulary schema: . <http://www.pjjk.net/semanticwp/book/the-day-of-the-triffids?36#id> a schema:Book ; schema:author [ a schema:Person ; schema:name "John Wyndham"@en-gb ; schema:url <http://www.pjjk.net/semanticwp/person/john-wyndham> ] ; schema:bookEdition "Popular penguins (2011)"@en-gb ; schema:bookFormat ""@en-gb ; schema:datePublished "2011-09-01"^^xsd:date ; schema:illustrator [ a schema:Person ; schema:name "John Griffiths"@en-gb ; schema:url <http://www.pjjk.net/semanticwp/person/john-griffiths> ] ; schema:isbn "0143566539"@en-gb ; schema:name "The day of the triffids"@en-gb ; schema:numberOfPages 256 ; schema:sameAs "http://www.amazon.co.uk/Day-Triffids-Popular-Penguins/dp/0143566539/"@en-gb, "https://books.google.co.uk/books?id=zlqAZwEACAAJ"@en-gb .
Further work: Ideas and a Problem
There’s a ton of other stuff that I can think of that could be done with this, from the simple, e.g. extend the range of types supported, to the challenging, e.g. exploring ways of importing data or facilitating / automating the creation of new post types from known ontologies, output in other formats, providing a SPARQL end point &c &c… Also, I suspect that much of what I have implemented in a theme would be better done as a plugin.
There is one big problem that I only vaguely see a way around, and that is illustrated above in the screenshot of the editing interface for the ‘about’ property. The schema.org/about property has an expected type of schema.org/Thing; schema.org types are hierarchical, which means the value for about can be a Thing or any subtype of Thing (which is to say of any type). This sort of thing isn’t unique to schema.org. However, the MetaBox plugin I use will only allow links to be made to posts of one specific type, and I suspect that reflects something about how WordPress organises posts of different custom types. I don’t think there is any way of asking it to show posts from a range of different types and I don’t think there is any way of saying that posts of type person are also of type thing and so on. In practice this means that at the moment I can only enter data that shows books as being about unspecific Things; I cannot, for example, say that a biography is a book about a Person. I can only see clunky ways around this.
Update: I noticed that you can pass an array of post types so that selection can be made from any one of them.
[Aside: the big consumers of schema data (Google, Bing, Yahoo, Yandex) will also permit text values for most properties and try to make what sense of it they can, so you could say that for any property either a string literal or a link to another resource should be permitted. This, I think, is a peculiarity of schema.org. The screenshot above of the data input form shows that the about field is repeated to provide the option of a text-only value, an approach hinting at one of the clunky unscalable solutions to the general problem described above.]
What next? I might set a student project around addressing some of these extensions. If you know a way around the selecting different type problem please do drop me a line. Other than that I can see myself extending this work slowly if it proves useful for other stuff, like creating examples of pages with schema.org or LRMI data in them. If anyone is really interested in the source code I could put it on github.
Update 02 Sep 2015:
I refactored the code so that most of the new php for creating new custom post types and setting up the forms to edit their properties is in plugin, and all the theme does is display the data entered with embedded RDFa.
I did set a student project around extending it, waiting to see if any student opts for it.
Two projects about describing courses
I’m currently involved in a couple of projects relating to representing course information as linked data / schema.org.
1. Course information in schema.org
As you may know the idea of using LRMI / schema.org for describing courses has been mooted several times over the last two or three years, here and on the main schema.org mail lists. Most recently, Wes Turner opened an issue on github which attracted some attention and some proposed solutions.
I lead a work package within the DCMI LRMI Task Group to try to take this forwards. To that end I and some colleagues in the Task Group have given some thought to what the scope and use cases to be addressed might be, mostly relating to course advertising and discovery. You can see our notes as a Google Doc, you should be able to add comments to this document and we would welcome your thoughts. In particular we would like to know whether there are any missing use cases or requirements. Other offers of help and ideas would also be welcome!
I plan to compare the derived requirements with the proposed solutions and with the data typically provided in web pages.
2. Institutional course data as linked data
Stefan Dietze commented on the schema.org course information work that it would be worth looking at similar existing vocabularies. That linked nicely with some other work that a colleague, Anna Grant, is undertaking, looking at how we might represent and use course data from our department as linked data (this is similar to some of the work I saw presented in the Linked Learning workshop in Florence). She is reviewing the relevant vocabularies that we can find (AIISO, TEACH, XCRI-CAP, CourseWare, MLO, CEDS). There is a working draft on which we would welcome comments.